Quick Links
Log files contain a lot of important data about how your infrastructure is performing, but when they're thousands of lines long, gaining useful insights from them can be hard. Log management tools help fix this problem.
Why Should I Care About Log Files?
Every connection to your web server is logged; anytime a user requests a resource, a line in the log file is written. You can use these kinds of logs to get a very accurate view of traffic coming in to your site. They doesn't offer any data about how the user interacts with the site, which is left to analytics tools, but they do tell you how your web server is handling each request.
The HTTP status code of the request is often logged, so these logs can be useful for tracking down broken links and errors that return 404 (which can affect your site's ranking when search engines like Google crawl the site), something that isn't returned with most analytics tools (as your page isn't even loaded).
Applications create logs of errors, which is useful for tracking down problems in the backend. If a particular API is causing errors, it will pop up in the log files very quickly. Your own applications will require you to implement your own logs, but there are plenty of logging libraries that make the process easier.
Unix keeps logs of everything that goes on with the system. Every command you enter is logged to
~/.bash_history
, every login attempt (including failed, possibly malicious ones) are logged to
/var/log/auth.log
, and most other system events will generate their own log files, usually stored in
/var/log/
.
The Problem: Too Many Servers, Too Many Logs

Most applications leave behind logs, a paper trail of what that application has been doing. Some applications, like web servers, can leave behind a lot of logs, which can get large enough to fill up your server's hard drive and need regular rotating.
One server is hard enough to manage, but managing logs spread across multiple servers can become an impossible task, requiring you to authenticate on each server and manually view the log files for that particular machine.
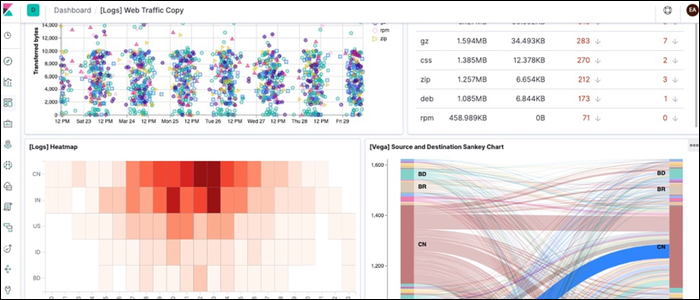
Log management tools are the solution to this problem, allowing you to concentrate your logs in one place and view them much more easily. Many services provide also visualization tools, so you won't have to go digging through ten thousand lines of text to find useful data.
How Do Log Management Tools Work?

A log management tool like Fluentd will run on a server somewhere, whether that's in the cloud behind a managed web interface or self hosted on your own systems. The server that this runs on is called an aggregator server, and collects logs from multiple external sources.
The process starts with ingest---log files from client system are fed into the aggregator with the help of a program called a log shipper. Log shippers like the
rsyslog
library are lightweight libraries that sit on client systems, and point towards the aggregate server.
Once the log files are ingested, what happens to them is up to the log management tool. For some tools, the simple collection of them is enough, and they can be sorted and fed into a time series database like InfluxDB for further analysis. For others, like Graylog, the service is built around the quality of their visualization and analytics tools.
What Tool Should I Use?

The Elastic Stack (also called the ELK stack) is a very popular logging platform. It's comprised of four different applications, all open source with the same developers. It's entirely free, but you'll need to host it yourself.
- Beats are lightweight log shippers designed to be installed on client machines, and send data to the other applications in the stack.
-
Logstash is the ingestion engine, which can take data from Beats or other programs such as
rsyslog - Elasticsearch is the engine at the center of the Elastic stack (after which the stack is named). It functions as a database for storing your logs (and other objects) and exposes a RESTful API for use in other applications.
- Kibana is the frontend for the Elastic Stack, and provides all of the visualization, charts, graphs, and search options for the end user.
Many of the tools in the Elastic Stack are fairly plug and play with other log management tools, so if you have a preference for something else, you can likely replace that item in the stack. Overall though, most tools and frameworks will follow the same general structure as the Elastic Stack---log shipper > ingestion engine > database > visualization tool.
Fluentd and Filebeat are alternative ingestion engines, and would replace Logstash in the stack. These can feed data into a time series database like InfluxDB, which has a built-in plugin for Grafana, an analytics and visualization platform.
Logwatch is a very basic command line utility that monitors your log files and sends you a daily report. It doesn't do any kind of collection, so it's ideal for single server setups that want some more insight into their server's logs.
Graylog replaces the Elastic Stack completely, and only requires external log shippers to ingest data. Their web interface supports creating custom charts and dashboards for monitoring your logs, but may be lacking compared to a setup with a proper database and Grafana.
SolarWinds Papertrail is a fully managed service that displays logs in realtime, which can be very useful when debugging issues with your servers. Their plans are fairly cheap, being segmented per GB and starting at just $7.
Splunk monitors just about everything surrounding your applications, including logs. If you want a comprehensive analytics suite, Splunk may be for you.
LogDNA is a simple log analysis tool with very cheap plans. If you're looking for an easy alternative to configuring an ELK stack, LogDNA can be set up quickly.