Quick Links
Newer isn't always better, and the
wget
command is proof. First released back in 1996, this application is still one of the best download managers on the planet. Whether you want to download a single file, an entire folder, or even mirror an entire website, wget lets you do it with just a few keystrokes.
Of course, there's a reason not everyone uses wget: it's a command line application, and as such takes a bit of time for beginners to learn. Here are the basics, so you can get started.
How to Install wget
Before you can use wget, you need to install it. How to do so varies depending on your computer:
- Most (if not all) Linux distros come with wget by default. So Linux users don't have to do anything!
-
macOS systems do not come with wget, but you can install command line tools using Homebrew. Once you've set up Homebrew, just run
brew install wget - Windows users don't have easy access to wget in the traditional Command Prompt, though Cygwin provides wget and other GNU utilities, and Windows 10's Ubuntu's Bash shell also comes with wget.
Once you've installed wget, you can start using it immediately from the command line. Let's download some files!
Download a Single File
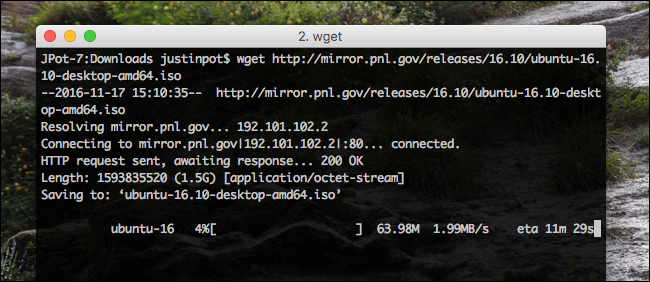
Let's start with something simple. Copy the URL for a file you'd like to download in your browser.

Now head back to the Terminal and type
wget
followed by the pasted URL. The file will download, and you'll see progress in realtime as it does.

Note that the file will download to your Terminal's current folder, so you'll want to
cd
to a different folder if you want it stored elsewhere. If you're not sure what that means, check out our guide to managing files from the command line. The article mentions Linux, but the concepts are the same on macOS systems, and Windows systems running Bash.
Continue an Incomplete Download
If, for whatever reason, you stopped a download before it could finish, don't worry: wget can pick up right where it left off. Just use this command:
wget -c file

The key here is
-c
, which is an "option" in command line parlance. This particular option tells wget that you'd like to continue an existing download.
Mirror an Entire Website
If you want to download an entire website, wget can do the job.
wget -m http://example.com

By default, this will download everything on the site example.com, but you're probably going to want to use a few more options for a usable mirror.
-
--convert-links -
--page-requisites -
--no-parent
Combine these options to taste, and you'll end up with a copy of any website that you can browse on your computer.
Note that mirroring an entire website on the modern Internet is going to take up a massive amount of space, so limit this to small sites unless you have near-unlimited storage.
Download an Entire Directory
If you're browsing an FTP server and find an entire folder you'd like to download, just run:
wget -r ftp://example.com/folder
The
r
in this case tells wget you want a recursive download. You can also include
--noparent
if you want to avoid downloading folders and files above the current level.
Download a List of Files at Once
If you can't find an entire folder of the downloads you want, wget can still help. Just put all of the download URLs into a single TXT file.

then point wget to that document with the
-i
option. Like this:
wget -i download.txt

Do this and your computer will download all files listed in the text document, which is handy if you want to leave a bunch of downloads running overnight.
A Few More Tricks
We could go on: wget offers a lot of options. But this tutorial is just intended to give you a launching off point. To learn more about what wget can do, type
man wget
in the terminal and read what comes up. You'll learn a lot.
Having said that, here are a few other options I think are neat:
-
If you want your download to run in the background, just include the option
-b -
If you want wget to keep trying to download even if there is a 404 error, use the option
-t 10 -
If you want to manage your bandwidth, the option
--limit-rate=200k
There's a lot more to learn here. You can look into downloading PHP source, or setting up an automated downloader, if you want to get more advanced.